🇩🇪 — Hi, ich bin Martin Ueding; Physiker, Maschinenlerner,
Softwareentwickler und engagiere mich für die Mobilitätswende. Ich habe
recht früh mit dem Programmieren angefangen und schreibe darüber im
Bereich »Code & Zahlen«. Im Physikstudium bin ich immer weiter in
die Computerphysik gegangen, meine Studiumsunterlagen sind noch immer
Teil dieser Webseite. Nach der Promotion bin ich in die Wirtschaft
gewechselt. Seit dem Abitur habe ich meine Wege mit dem Fahrrad
erledigt, Radtouren unternommen und irgendwann auch Radreisen.
Inzwischen bin ich auch Aktiver im Radentscheid Bonn.
Aktuell schreibe ich am meisten zu Verkehrsthemen, manchmal auch noch
über Wissenschaft, Maschinenlernen oder anderen Dingen, die mir
einfallen. Die eher technischen Dinge schreibe ich meist auf Englisch,
den Rest auf Deutsch.
Man kann mich per E-Mail, Threema oder Telegram kontaktieren, oder mich auf
Mastodon, Pixelfed
und GitHub finden.
🇺🇸 — Hey, I am Martin Ueding, a physicist, software developer,
machine learning researcher and a traffic policy activist from Germany.
On my blog you can find all my physics study
material, mostly English articles about code and numbers. The
articles about traffic policy
are in German.
You can contact me via E-mail, Threema or Telegram. You can also find me on Mastodon, Pixelfed
and GitHub.
My company has solid security policies which seem to be oriented at best practices. And I am very glad that they don't enforce nonsense policies that would actually weaken the passwords that users choose. That of course isn't the case with every company. There is one particularly arcane case. They have these rules for passwords:
Weiterlesen…
Freie Fahrt für freie Bürger ist das Leitbild deutscher Mobilität. Es geht also um Freiheit, und die Partei mit »Frei« im Namen weiß, ist vor allem der freie Markt das für die Realisierung wichtige Element. Wie auch in anderen Lebensbereichen wird die unsichtbare Hand des Marktes aber von links-grünen Fortschrittsfeinden aufgehalten, sodass am Ende der Verkehr aufgehalten wird.
Weiterlesen…
Ich kann normalerweise ganz gut hören, ob irgendwo noch ein Fenster geöffnet ist. Der Straßenlärm klingt dann ganz anders. Mit geschlossenen Fenstern ist es dann deutlich dumpfer. In meiner neuen Wohnung habe ich aber häufig den Eindruck, dass die Fenster nicht ganz geschlossen waren. Da es sich um Plastikfenster handelt, kann man das eigentlich nicht falsch machen. Aber vorbeifahrende Autos sind irgendwie immer so präsent …
Weiterlesen…
My camera is a rather old DSLR which still uses CF cards. In order to get the images, I would take it out of the camera body, put it into a card reader and then transfer the images. Afterwards the card was inserted back into the camera body. This has worked fine for years, but one day the card reader would not work any more. I didn't understand, and just bought a new card reader. One day in 2016, the new card reader stopped working. I then looked into the card reader and saw that a pin was bent.
Weiterlesen…
Scythe is a board game from the engine builder genre. Is a rather complicated game as there are different types of entities and actions around. It is about collecting resources, deploying the hero, workers, mechs and buildings, moving them around, fighting with others, accomplishing achievements. In the end one obtains a score based on the number of achievements, controlled hexes and resources as well as left-over money and some bonus points.
Weiterlesen…
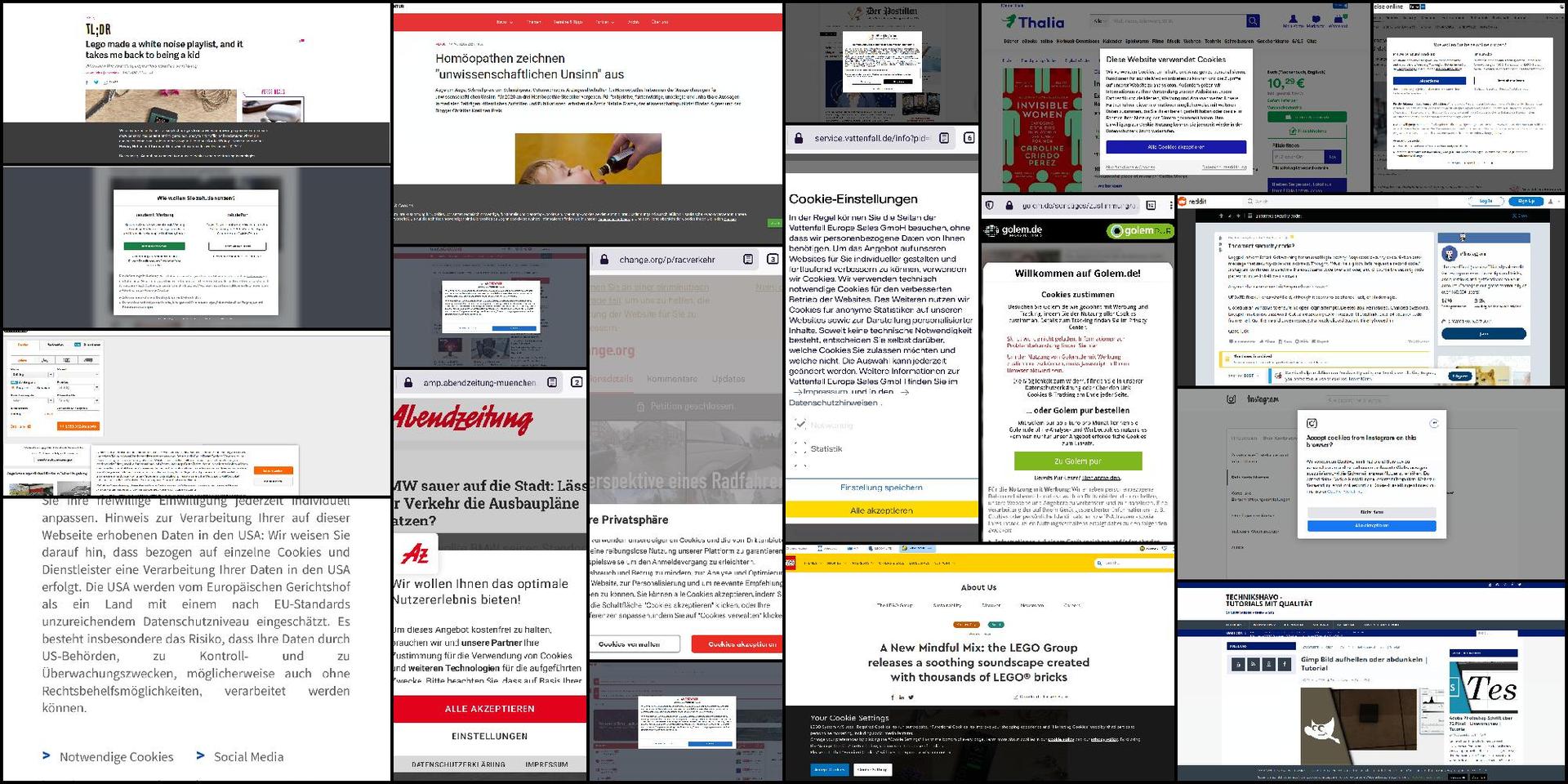
As an internet user, you of course have seen more of these cookie banners than you had liked to. They are on virtually all sites that I browse and they totally annoy me. A decade ago websites had those pesky adversisement pop-ups, now they have those banners that show up seconds after the site has loaded enough to see the content.
Weiterlesen…
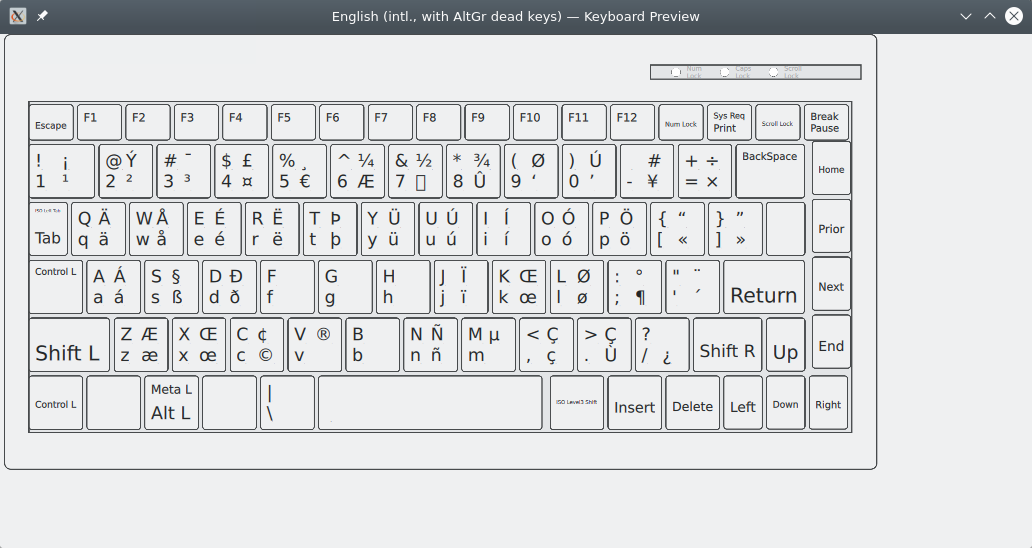
I have been using the ANSI keyboard layout for many years now and stronly prefer it over the ISO layout. The ANSI layout has the smaller enter button and a longer left shift key. Then I use the US international layout such that I can create German umlaut characters and other fancy things. On top of that I use the Linux compose key to create even more characters.
Weiterlesen…
I have a hate-love relationship with Bluetooth. I would like to like it, but it always turns out to be frustrating. The idea of having a short-range wireless standard which allows coupling devices to each other is great. And on humble days I find it amazing that it works to the extent that it does.
Weiterlesen…
For years I am a user of Stack Overflow and network of sites called Stack Exchange. My network profile has a long list of accounts that I have within the network. The sheer amount of sites became really annoying for me years ago, and today's experience was the straw that broke the camel's back.
Weiterlesen…