Clean Architecture for Vigilant Crypto Snatch
I have recently finished Clean Architecture1. In the book Robert C. Martin presents a certain way to organize components of a program. It consists of a series of concentric rings, where dependencies are only inward. There is a core of central business rules in the middle, depending on nothing else. Then there are use-cases around that, depending only on the core business rules. And then even further out are adapters to other libraries and interfaces. Since there are no dependencies on concrete things, these can easily be exchanged for something else, be substituted for tests and so on.
For years I wanted to improve the design of the software that I work on, so I have been reading books like that. And today I want to apply the ideas to my hobby project Vigilant Crypto Snatch to get some experience with the architecture. The idea is to first draw the architecture of the current system, then clean it step by step.
Original architecture
The current architecture looks roughly like this:

There are a couple of things that I dislike. The most striking is that my core data classes Trade and Price depend on an external library, SQL Alchemy:
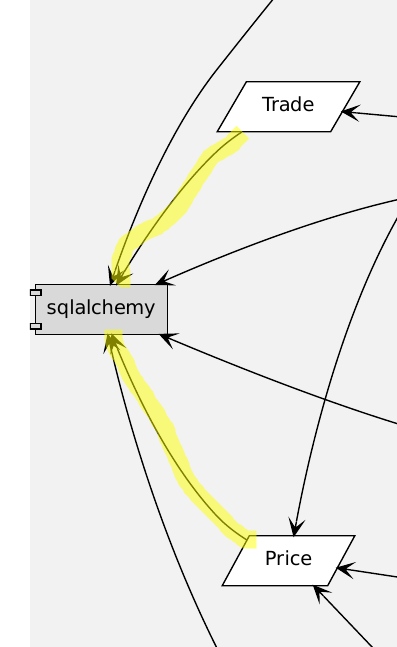
This is one the common things that Martin mentions in his book, that the ORM frameworks want you to inherit from their base classes. But that then couples the whole application to this external library.
When I was testing my application, I would spin up an in-memory database and use that. Several parts of the code directly use the SQL Alchemy API, so they are also coupled to it. The trigger that bought something would directly write to the database, and the historical source would directly look into the database.
On the other hand I am quite happy with the way that I had formed the Marketplace interface. It does not depend on either the Kraken or Bitstamp libraries, there are concrete implementation depending on them. And then the main loop uses a factory to construct a concrete Marketplace instance, but doesn't use anything but the abstract interface.
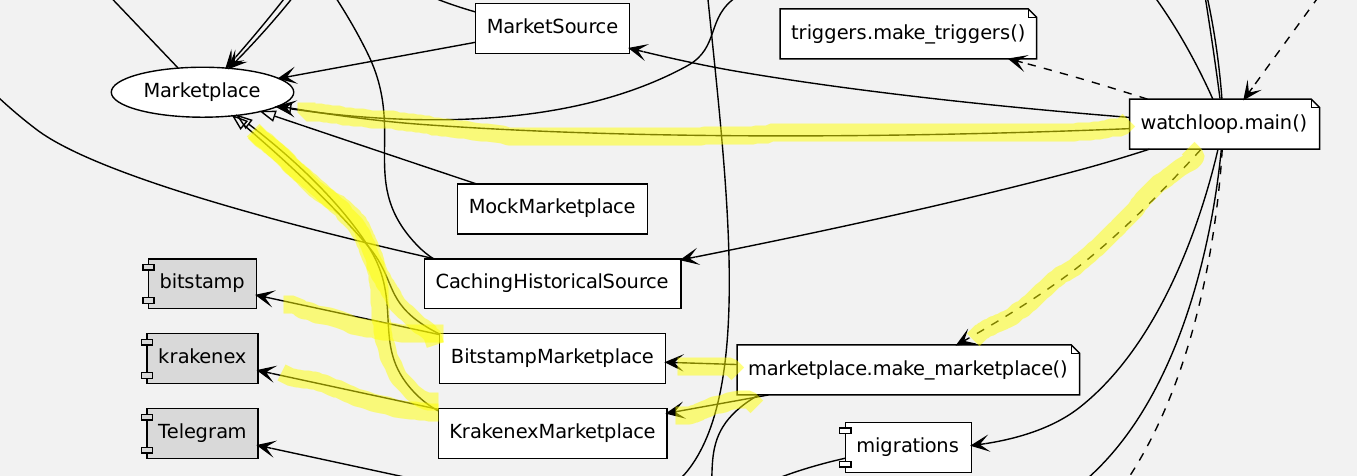
This is how I would like the code to be. This is now decoupled and might merit the predicate “clean”.
Test suite
The current test suite has 15 tests:
$ poetry run pytest ================================================ test session starts ================================================= platform linux -- Python 3.9.7, pytest-6.2.4, py-1.10.0, pluggy-0.13.1 rootdir: /home/mu/Projekte/vigilant-crypto-snatch collected 15 items tests/test_checkin_trigger.py . [ 6%] tests/test_drop_trigger.py ... [ 26%] tests/test_drop_trigger_with_percentage.py . [ 33%] tests/test_failure_timeout.py ... [ 53%] tests/test_telegram.py .. [ 66%] tests/test_trigger_start.py . [ 73%] tests/test_true_trigger.py .... [100%] ================================================= 15 passed in 0.68s =================================================
I would want to have more tests, and also integrate the tests more closely with the code, instead of having it reside in a separate module.
Independent core data
I want to have Trade and Price as entities which do not depend on anything else. They shall be Python data classes.
For the Price it looks like this, super simple:
@dataclasses.dataclass() class Price: id: int timestamp: datetime.datetime last: float coin: str fiat: str def __str__(self): return f"{self.timestamp}: {self.last} {self.fiat}/{self.coin}"
Abstract data store
And then I need an abstraction around the persistence layer. So first I need to figure out how the SQL Alchemy database is used:
- Its fields are used to create the classes Trade and Price.
- I need to initialize a new DB session.
- Add a trade to the database.
- Add a price to the database.
- In the
DatabaseHistoricalSourceI query the DB for prices which are around given point in time. - After the trigger simulation I need to obtain all trades, I convert them to a Pandas data frame.
- In the
BuyTriggerI want to find out whether a particular trigger has been triggered within the cooldown period. - I want to clean old prices from the database.
These are things which I can offer in an abstract data persistence interface using only my core entities:
class Datastore: def get_price_around( self, then: datetime.datetime, tolerance: datetime.timedelta ) -> vigilant_crypto_snatch.core.Price: raise NotImplementedError() def was_triggered_since(self, trigger_name: str, then: datetime.datetime) -> bool: raise NotImplementedError() def get_all_trades(self) -> List[vigilant_crypto_snatch.core.Price]: raise NotImplementedError() def clean_old(self, before: datetime.datetime): raise NotImplementedError()
This again is really simple, there are no external dependencies. This part of the architecture now looks really simple:

And then with the SQL Alchemy data store added, we have another component, which only couples one way. This way the my core entities do not depend on the external library (now in dark).
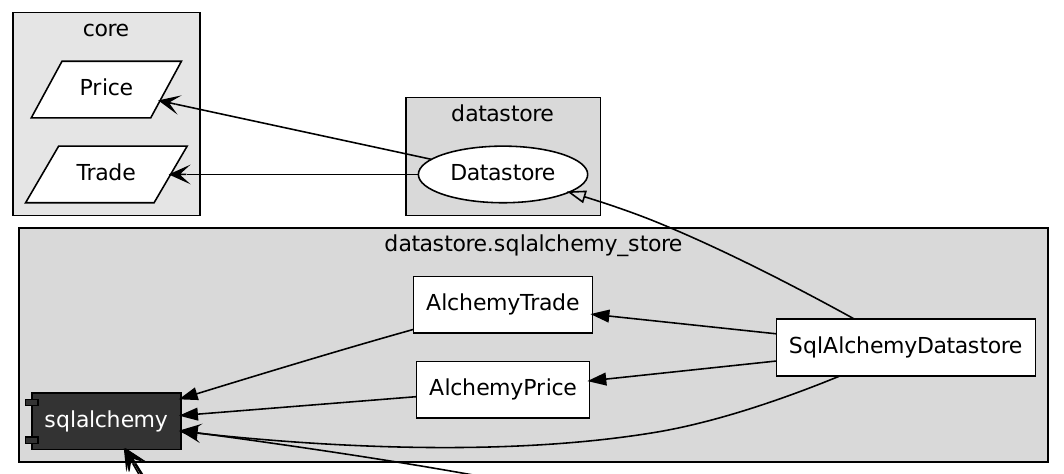
This is what I wanted!
It turned out to be quite some pain to remove all the explicit dependencies to SQL Alchemy there. In the beginning I thought that depending on this library would not be such a big deal, but I was mistaken. Now with the new design it is much cleaner, and it is amazing how ingrained it got into the code base. In a way it is good that I pulled it out now, it would only have gotten worse in the future.
Grouping other modules
I have then also put some of the modules into sub-packages. This way I can have one interface to the outside with the __init__.py file, and use other things internally. This makes the interfaces smaller. And given that they contain other types, they become deeper. This is what Ousterhout wrote in A Philosophy of Software Design2. He doesn't feel as bad about coupling as other authors, his gauge rather is whether modules are deep or shallow. And deeper modules are easier to use by others, because their surface is smaller. They still have a lot of internal cohesion, but that is okay for a module.
With these changes, the module and package structure of the project looks like this:
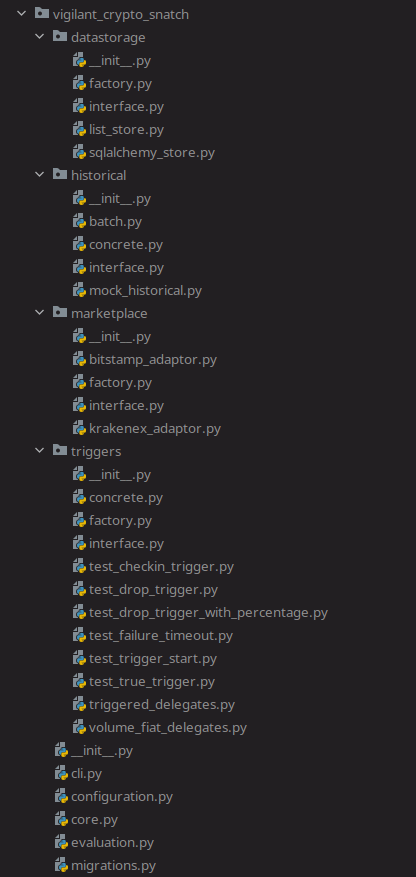
There are a few more modules at the bottom omitted. But the tests are now within the packages whose modules are under test. This means that I don't have to export these modules in the package, but rather it is self-contained. PyTest will still find the tests, of course.
Trigger specification
The user specifies the triggers as a key-value mapping (dict) in the configuration file (YAML). These dicts are directly passed to the factory, which then constructs the trigger from that. What I lack is a trigger specification as one of my core entities.
Take a look at the factory function before I introduce this trigger specification:
def make_buy_trigger( datastore: datastorage.Datastore, source: historical.HistoricalSource, market: marketplace.Marketplace, trigger_spec: Dict, dry_run: bool = False, ) -> BuyTrigger: logger.debug(f"Processing trigger spec: {trigger_spec}") delay_minutes = get_minutes(trigger_spec, "delay") cooldown_minutes = get_minutes(trigger_spec, "cooldown") if cooldown_minutes is None: logger.critical(f"Trigger needs to have a cooldown: {trigger_spec}") sys.exit(1) # We first need to construct the `TriggeredDelegate` and find out which type it is. triggered_delegate: TriggeredDelegate if delay_minutes is not None and "drop_percentage" in trigger_spec: triggered_delegate = DropTriggeredDelegate( coin=trigger_spec["coin"].upper(), fiat=trigger_spec["fiat"].upper(), delay_minutes=delay_minutes, drop_percentage=trigger_spec["drop_percentage"], source=source, ) else: triggered_delegate = TrueTriggeredDelegate() logger.debug(f"Constructed: {triggered_delegate}") # Then we need the `VolumeFiatDelegate`. volume_fiat_delegate: VolumeFiatDelegate if "volume_fiat" in trigger_spec: volume_fiat_delegate = FixedVolumeFiatDelegate(trigger_spec["volume_fiat"]) elif "percentage_fiat" in trigger_spec: volume_fiat_delegate = RatioVolumeFiatDelegate( trigger_spec["fiat"].upper(), trigger_spec["percentage_fiat"], market ) else: raise RuntimeError("Could not determine fiat volume strategy from config.") logger.debug(f"Constructed: {volume_fiat_delegate}") result = BuyTrigger( datastore=datastore, source=source, market=market, coin=trigger_spec["coin"].upper(), fiat=trigger_spec["fiat"].upper(), cooldown_minutes=cooldown_minutes, triggered_delegate=triggered_delegate, volume_fiat_delegate=volume_fiat_delegate, name=trigger_spec.get("name", None), start=get_start(trigger_spec), dry_run=dry_run, ) logger.debug(f"Constructed trigger: {result.get_name()}") return result
It is a very long function, and it also has calls to get_minutes, which normalizes entries from the configuration. That is a different concern. The make_buy_trigger() function would need to change when the configuration format changes. But it would also need to change if the triggers change. And the open-closed principle states that each class should have only one reason to change.
Now I have a TriggerSpec data class:
@dataclasses.dataclass() class TriggerSpec: name: Optional[str] coin: str fiat: str cooldown_minutes: int delay_minutes: Optional[int] drop_percentage: Optional[float] volume_fiat: Optional[float] percentage_fiat: Optional[float] start: Optional[datetime.datetime]
And with that I could simplify the make_buy_trigger() function, while still retaining the same signature as before:
def make_buy_trigger( datastore: datastorage.Datastore, source: historical.HistoricalSource, market: marketplace.Marketplace, trigger_spec_dict: Dict, dry_run: bool = False, ) -> BuyTrigger: logger.debug(f"Processing trigger spec: {trigger_spec_dict}") trigger_spec = configuration.parse_trigger_spec(trigger_spec_dict) # We first need to construct the `TriggeredDelegate` and find out which type it is. triggered_delegate: TriggeredDelegate if ( trigger_spec.delay_minutes is not None and trigger_spec.drop_percentage is not None ): triggered_delegate = DropTriggeredDelegate( coin=trigger_spec.coin, fiat=trigger_spec.fiat, delay_minutes=trigger_spec.delay_minutes, drop_percentage=trigger_spec.drop_percentage, source=source, ) else: triggered_delegate = TrueTriggeredDelegate() logger.debug(f"Constructed: {triggered_delegate}") # Then we need the `VolumeFiatDelegate`. volume_fiat_delegate: VolumeFiatDelegate if trigger_spec.volume_fiat is not None: volume_fiat_delegate = FixedVolumeFiatDelegate(trigger_spec.volume_fiat) elif trigger_spec.percentage_fiat is not None: volume_fiat_delegate = RatioVolumeFiatDelegate( trigger_spec.fiat, trigger_spec.percentage_fiat, market ) else: raise RuntimeError("Could not determine fiat volume strategy from config.") logger.debug(f"Constructed: {volume_fiat_delegate}") result = BuyTrigger( datastore=datastore, source=source, market=market, coin=trigger_spec.coin, fiat=trigger_spec.fiat, cooldown_minutes=trigger_spec.cooldown_minutes, triggered_delegate=triggered_delegate, volume_fiat_delegate=volume_fiat_delegate, name=trigger_spec.name, start=trigger_spec.start, dry_run=dry_run, ) logger.debug(f"Constructed trigger: {result.get_name()}") return result
This function isn't really shorter, but it is now more focused. It just takes the fields from the TriggerSpec and assembles the delegates, but it doesn't also parse the configuration dict.
Intermediate architecture
With these cleaning steps, the architecture now looks like this:

It doesn't feel perfect, but at least the core entities are all to the left side. They depend on nothing else. The command line entr./y point is on the far right, and it depends on the modules which drive the use cases. This seems to be a good improvement.
I've cleaned a bit more, added some more tests and then tried out pydeps to automatically generate a module import graph for me:

One interesting feature is to output the cycles:

Cycles are never good, so I need to figure out how to resolve this.
I've done a bit of research, and according to this well-written article it seems that it is indeed the way to go.
Adding more tests
Now that I have a few things decoupled, I can easily write some more tests. I can better test the triggers, I can test the configuration parsing into TriggerSpec instances. The decoupling has introduced more lines of code, but it also increased the testability. And that is really great to improve the quality of the code.
And this is the test suite with a few more tests:
$ poetry run pytest ================================================ test session starts ================================================= platform linux -- Python 3.9.7, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 rootdir: /home/mu/Projekte/vigilant-crypto-snatch collected 33 items src/vigilant_crypto_snatch/configuration/triggers_test.py .......... [ 30%] src/vigilant_crypto_snatch/datastorage/test_implementations.py ........ [ 54%] src/vigilant_crypto_snatch/telegram/message_helper_test.py .. [ 60%] src/vigilant_crypto_snatch/triggers/test_checkin_trigger.py . [ 63%] src/vigilant_crypto_snatch/triggers/test_drop_trigger.py ... [ 72%] src/vigilant_crypto_snatch/triggers/test_drop_trigger_with_percentage.py . [ 75%] src/vigilant_crypto_snatch/triggers/test_failure_timeout.py ... [ 84%] src/vigilant_crypto_snatch/triggers/test_trigger_start.py . [ 87%] src/vigilant_crypto_snatch/triggers/test_true_trigger.py .... [100%] ================================================= 33 passed in 0.71s =================================================
Lessons learned
I have spend more than a full working day on cleaning this architecture and writing this blog post about it. Not writing the blog post would not have been so much faster, because I usually take notes anyway.
Given that this whole project just has 2200 source lines of code, it took an incredible amount of time to get the SQL Alchemy dependency factored out. There are no other excuses, I know the Python language, I know the Dependency Inversion Principle, so the time it took was actually spent trying to figure out how to do the new design and doing all the necessary refactoring. Because the tests run within seconds, my iteration velocity was quite high.
This means that on any larger project with a fatter test suite, this is going to take even longer for the simplest changes in the architecture. Initially adding the indirection via the Datastore interface would not have cost me that much time. This clearly shows how much more expensive it becomes to change the architecture afterwards. And also it provides a good motivation to regularly clean the architecture to prevent the build-up of technical dept, like one has seen here.