receipt-reader
Whenever I go shopping, I get those thermo-printed paper receipts. In principle, those contain all the information about the products that I bought. At home I have a big pile of paper receipts. Ideally I could extract at least the information from the supermarket receipts and generate a statistic about the products that I have bought. I am not sure how useful that is in practice, it would be at least cool.
The ingredients are there: I have a scanner, Fedora has Tesseract and I know enough Python to assemble that together. A first problem is the arbitrary layout of all the different stores. Some have one line per item, others have two lines per items. This is perhaps something that one needs to take into account.
Recognition efficiency
My major problem has been the recognition rate of Tesseract with the receipts.
The font on the receipts is not really great since letters look very similar.
The software has big trouble to tell apart the "1" and the "l". A receipt from
ALDI looks like this when I scan it with scanimage:
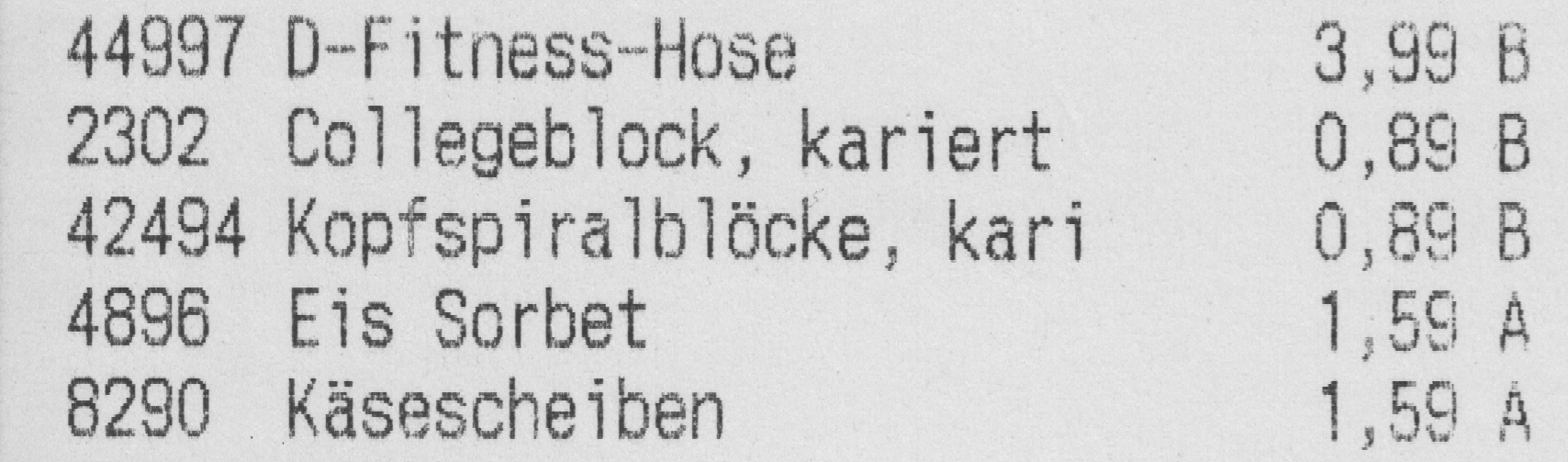
First I have adjusted the levels a bit and got this:

The recognized text is then this:
44887 0wFitnesemHoee 8,88 8 - _ \ ‘ , 2802 Coiiagebieck, kariert 0,88 8 _ ‘ « 42484 Kapfspiraibiöeke, keri 0,88 8 4888 Eis Sorbet 1,88 A . ' ' 8280 _Käeescheiben 1,88 8 . . ‘ -
You see that the prices are pretty off. Also there is noise that cannot be seen on the images shown here. This goes away mostly when the image is cropped.
The next step I tried has been erosion:
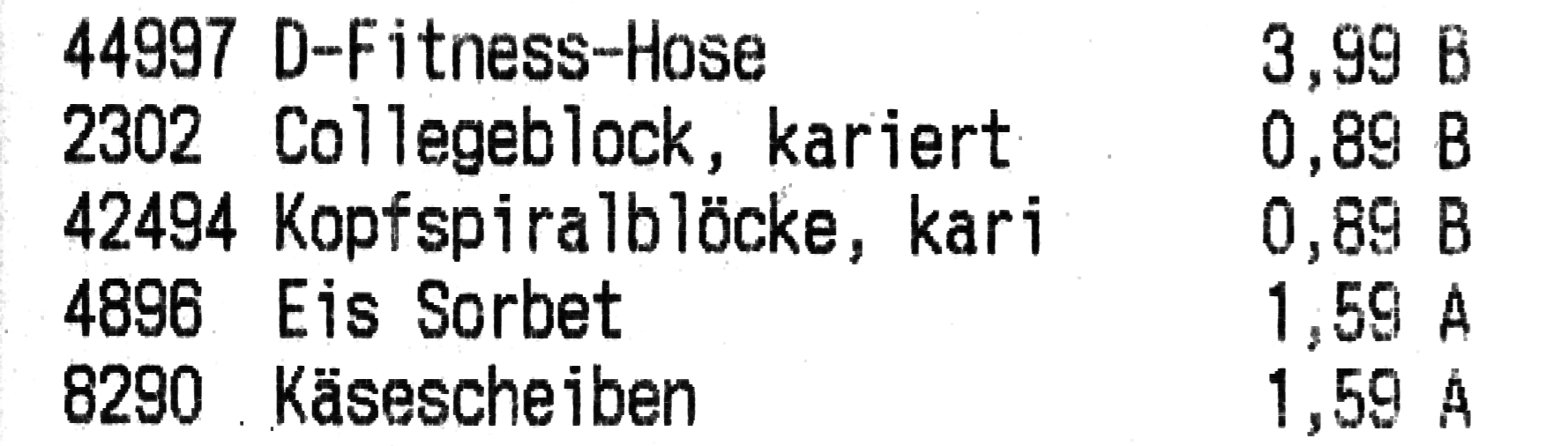
This leads to slightly better recognition:
44997 DwFitness—Hose 3,99 8 2302 Coiiegebiock, kariert 0,89 B 42494 Kopfspiraihiöcke, kari 0,89 B 4896 Eis Sorbet 1,59 A 8290 „Käsescheiben 1,59 9
You can see that there are still 8 and B mixed up. At least the prices are
correct now. The names of the articles do not quite match the intention, the
VAT classes (A and B at the end) are not picked up correctly either.
Filtering all this with a regular expression,
(?P<id>\d+)\s+(?P<name>.+?)\s+(?P<price>\d+,\d+), then gives the following:
{'id': '44997', 'price': '3,99', 'name': 'DwFitness—Hose'} {'id': '2302', 'price': '0,89', 'name': 'Coiiegebiock, kariert'} {'id': '42494', 'price': '0,89', 'name': 'Kopfspiraihiöcke, kari'} {'id': '4896', 'price': '1,59', 'name': 'Eis Sorbet'} {'id': '8290', 'price': '1,59', 'name': '„Käsescheiben'}
That is somewhat nice, but still not perfect. The inherent problem comes apparent when one looks at the part where I bought the same yogurt three times:
{'id': '2753', 'price': '0,29', 'name': 'Premium—Joghurt'} {'id': '2753', 'price': '0,29', 'name': 'Premium-Joghurt'} {'id': '2753', 'price': '0,29', 'name': 'Premium-Joghurt -'}
By the id field I should be able to tell that those are the same articles.
That would require a lot of fuzzy logic that would get it right. But not all
stores print their article numbers on the receipts. This would mean different
kind of fuzzyness.
Layouts
The layouts of the whole receipts differs greatly between the different stores. So this is from the C1000 supermarket in the Netherlands:

And this from a local hardware store:
And that is from another hardware store:

I doubt that it would make sense to let the software recognize which store a receipt comes from. It is probably best to crop the receipts to the area which contains the items and tell it which store it is from. This is a but more manual labor than I intended to put into this.
Source code
The little source code is in the git repo: https://github.com/martin-ueding/receipt-reader
Conclusion
This has been a nice idea to try out. I had not much success yet and there are a lot of parameters to tune in the initial image preparation. Ideally I would just slap my receipts on the scanner and let the software do all the rest. It seems that this would require huge amounts of work until that works for a given receipt format.
There must be a better way. I already pay with my debit card. There the store already has some hundred characters to specify that end up on my bank account. It would be really awesome if they could supply the information on the receipt in a JSON form to my bank which would collect that data for me then. The format should have some standard fields (like name, EAN, price, multiplicity) and then an arbitrary amount of extra information that the store wants to provide.
It would raise some privacy concerns, though: The bank currently only knows how much money I spend at each store. With that JSON data it would learn what I buy and perhaps make lifestyle and risk assessments based on that. If that data is then sold to insurance agencies, I would be off as bad as one is with a PayBack Card or some other royalty system.
With asymmetric encryption, one could solve that problem. Then there is an encrypted field in my bank statements that only I could decrypt. As unlikely as the JSON data is in the first place, I highly doubt that any of this will come in the foreseeable future with my regular bank and debit cards. When paying with NFC and some new technology from say Apple or Google, this might as well change.