Lacking Uncertainty Estimations in Natural Language Processing Papers
My university background is physics, which is an empirical science. All measurements or derived quantities must be quoted with an error estimate. This should ideally include both a statistical and a systematic error. If you take a look at the paper from my thesis, you will find this table:
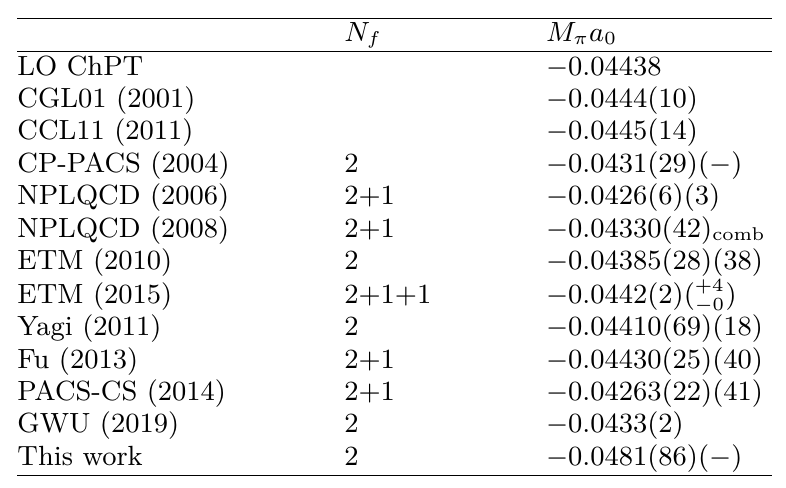
It contains the comparison of a certain quantity (pion scattering length) from various other publications and our result. There are uncertainties given, either as a combined value or as separate statistical and systematic ones. One result by the ETMC even has asymmetric systematic errors quotes. You can look at these numbers and figure out whether the result from that work lies within the error budget of the other works. The raw table isn't as meaningful as a plot, but you could create a plot from the table. And one can see that our result has a one standard deviation confidence interval of $[-0.0567, -0.0395]$, so it easily encompasses all previous work. Also it has the largest error of all results, so it is the least precise addition to the field. This is okay as it was just an auxiliary result and we weren't aiming for precision there.
In my new field, natural language processing (NLP), I cannot say the same thing. There are no error estimates whatsoever! And it really annoys me, you cannot really derive any conclusion from the data. Take for instance the paper on BERT. They show a table where they compare two variants of the BERT model with other language models in various tasks:
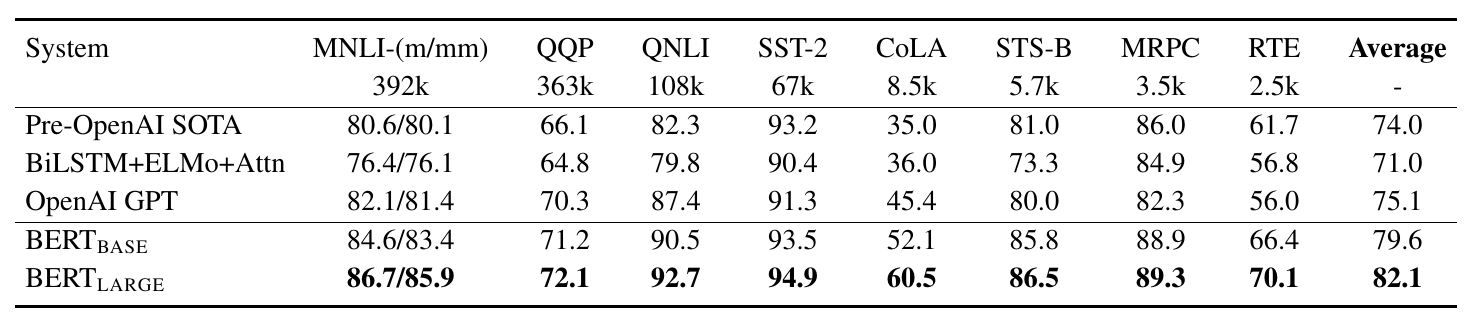
A common thing in the field is to mark the best value in bold such that one easily spot it. But is that really meaningful within error estimates? In the QQP task the margin to the OpenAI GPT model is not that large, just 1.8 points. Is that large? Is that small? Without an estimation of uncertainty, we just have no way of knowing.
Looking at this table one can draw the conclusion that the BERT-Large model is the best one there is. It performs the best on all the tasks. But these tasks are evaluated on a test set, and that is not representative for all the things that one could ask the language model. The average over different tasks has less uncertainty, but we also don't know whether that is a big improvement or not.
If we were to look at the distribution of the difference between the new model versus each older model, then we would start to see something that we could test with a $T$-test or $Z$-test. If that distribution would be clearly away from zero, we would see a significant improvement and could see the tasks as independent measurements. But they haven't done that, and that table is rather suggestive in this state.
The same pattern is present in all other papers that I have read. Apparently there is just the hope that the numbers are accurate to the quoted precision and that using a different test set for each of the tasks would not change the numbers. Without an actual quantified uncertainty, there is no way of knowing.
In physics I'd tell everyone who approaches me with a table without error estimates or a plot without error bars to add these and come back. In NLP apparently I am one of very few people who have a problem with this lack of scientific robustness.